Here is a short description of the most significant new features of the recently released TextConverter 4.5.
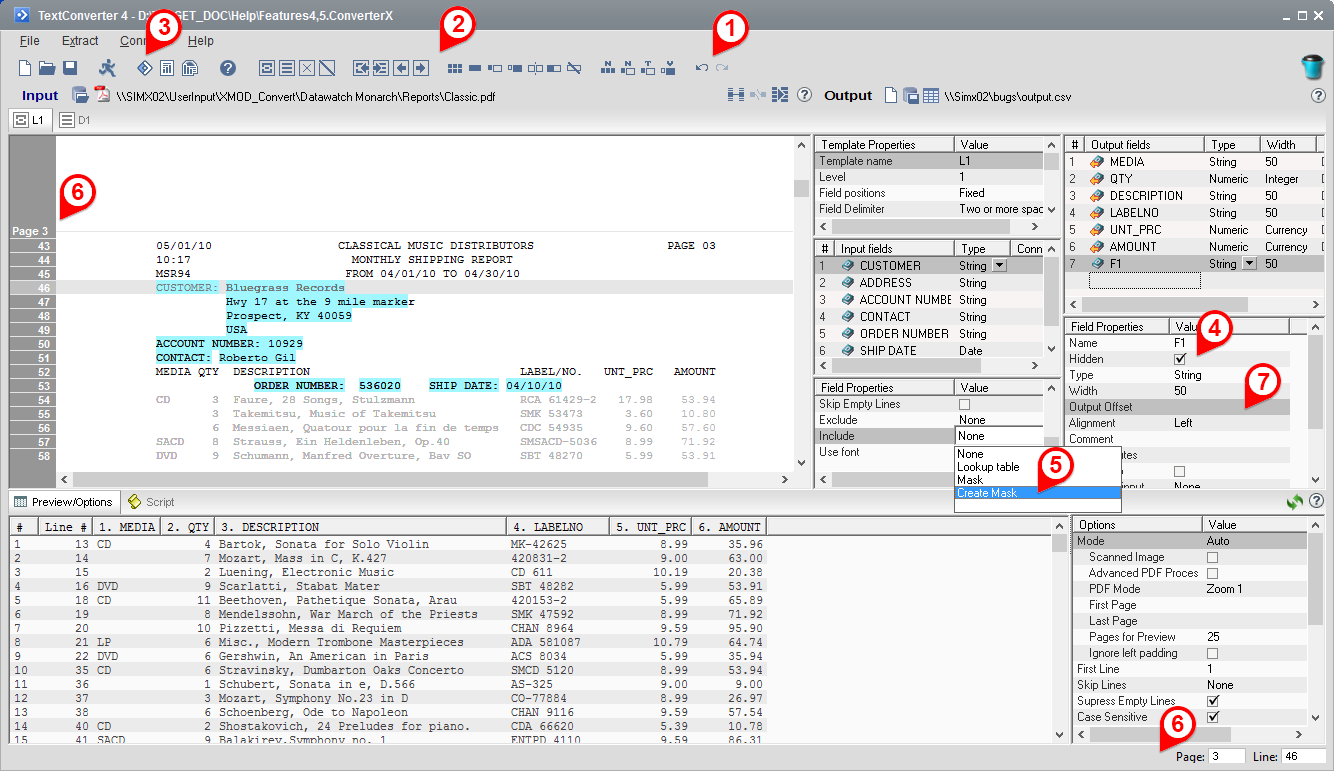
1. Full UNDO/REDO support. As opposed to the previous version where the UNDO/REDO functionality was supported only in the Script Editor, in the new version 4.5 the UNDO/REDO function covers full TextConverter functionality including all the visual actions.
2. Friendlier user interface. An extra set of buttons at the toolbar provides access to the most frequently used workflow actions related to the templates and fields maniulations.
3. Summary output. A new component DbConverter provides visual means for data merging, splitting, updating, mapping, and more. It allows to join multiple tables from unlimited number of data sources across different databases and protocols.
4. Hidden output fields. This feature allows to conveniently store intermediate information in the "hidden" output fields. The term "hidden" means that the fields marked as "Hidden", although fully functional inside TextConverter are not present in the output table.
5. Automated mask generation for input and output filters. This feature helps users to improve their skills in using regular expressions by automatically generating the suggested regular expression strings based on the selection in the input preview.
6. Simplified input file navigation using page and line controls. Now, the current page and line numbers are shown (for PDF input files) at the right side of the status bar as well as on the left shoulder of the input preview. The status controls enable navigation to any desired page or line.
7. More precise control over positional output. The two new output field properties (Output Offset and Alignment) now provide full control over the layout of output text files with positional layout.
8. Data extraction from password secured Excel files. Now TextConverter can process password protected Excel files. The password could be set using the corresponding function this.SetPassword in script.
9. Script control over all visual properties. For advanced users we have implemented script level control over search tags and other data extraction properties in order to handle extraction cases where UI or mask based setups are not enough.